



Bias In Data & Opinions
Facing the Inevitable Consequences of Bias


First, Let Us Tie The Knots Together
The Obvious:
By the time you are done reading this piece, I have no doubt you will say to yourselves, “Well, that was kind of obvious.” And I will agree. The message of this piece may be unmistakable when you finish it, but it is still massively overlooked. I admit this piece is a bit esoteric, quirky, and geeky. I also strongly feel the message should be seriously considered, even if such a message is delivered differently than usual.
Let Us Begin With Technology
As some know, I come from the world of technology. My specific area of expertise has been in VR and, since 2015, the building blocks of AI. I became fascinated with Chaos and Complexity Theory, Emergence & Singularity Theory, and Sentiment & Emotional Analysis, and have been extensively published in these areas. (And anyone on Substack or off who wishes to discuss these things and other matters of AI with me, please do not hesitate to get in touch. But be warned. I will talk your ear off!)
From time to time, along with my journal papers, I would publish smaller articles on Medium dealing with some particular aspects of AI. (I have a fairly respectable following on Medium based on these pieces). They were summaries of specific sections in published journal articles. I would also “dummy down” the information presented and, when possible, place simple Wikipedia articles in the footnotes instead of the lengthy reading material that usually appears in journal articles so that the public who reads such pieces can get to the information for free. (You will see those here.)
Among the most misunderstood areas of AI, and indeed the new-wave phenomenon of ChatGPT and all the spinoffs, is what exactly information is. This lies at the heart of any AI system and the algorithms involved in Large Language Modules (LLMs). In short, if one does not understand the essentials of “information theory,” any attempt at interpreting information is doomed to failure.
One of the smaller pieces I published on Medium on Apr 19, 2022, was entitled “Bias — The Achilles Heel Of Data Analysis: Facing the Inevitable Consequences of Bias in Data.” Recently, for reasons that are beyond me, this article has received a significant uptick in reads and likes. So I revisited it and realized this article's message has significance here.
This article on “Bias” appears below, But for now, let the term “Bias” simmer below the surface for a bit.
Now We Move On To Substack & Writing
So why am I writing an article on AI, information theory, and BIAS in a newsletter named “The View From Israel.”? Why am I not starting a new newsletter on AI and VR and publishing all my articles and pieces there? (Excellent idea, btw.)
What becomes apparent on Substack after acclimating oneself to the system and how it works, among the excellent written pieces and those that are not, more than other sites, is the plethora of opinion pieces presented as “truth” and “pure data.” Perhaps this is because the nature of the articles and posts produced here are serious writing and not just social media posts on X, Stories, or Instagram. However, whatever the reason, it is apparent here.
What is also clear is that all of us, every one of us, including myself, are writing from a POV. By definition, a “Point of View” implies “bias.” There is no objective truth in a POV. And yet, many here seem to be bent on proving everything they write, everything they quote, and all their opinions are objective truth.
Further complicating matters is the line between a POV and misrepresentation or outright “lies.” We tend to call "lies,” by the term “fake news” these days, so I will leave you to choose the term you wish to use.
Lies or fake news are a problem. The one reproducing these statements can believe them, and this can be attributed to the writer's POV or an honest misjudgment. Or, more nefarious, the individual can be the source of such lies.
This happens in every subject under the heavens. It indeed has permeated every aspect of political discussion and, most certainly, the subject of Israel and the war with Hamas. I am not a political pundit, though one of the examples below in the article on Bias is based on the 2016 presidential elections in the US.
However, I review the “Notes” section in Substack every morning and am always surprised at the authors passing their own POV and Bias as “absolute truth.” Not an opinion, not a personal note, but pure objective truth.
Therefore, I am presenting my readers with the article on Bias. I have not changed it in any way.
The article on Bias below is technological and a bit geeky.
Yet, I have faith in my readers that they can follow completely.
I have faith that you will get the message.
Bias
In a previous article, I discussed Information Theory and Claude Shannon’s contribution to our understanding of ‘information.’ In it, we discovered that ‘meaning’ has nothing to do with the information, as paradoxical as that may seem. This was Shannon's genius as he postulated that information is ‘noise’ and ‘surprise.’ Indeed, meaning will confuse the possibility of analyzing information. Now, we must deal with one of the significant flaws in how information is collected, categorized, and analyzed.
Data analytics has a colossal job in determining what is actually in the data. However, the quest for data purity does not end there.
It is essential to deal with possible bias in and about the actual data. One must be wary of two significant types of bias in analytics and AI.
Bias In the Data
In analyzing data for any system, specifically for an AI system, one must be aware of the origin of said data. For example, applying medical information from a massive data lake of 90 percent male health statistics to a majority female population will probably produce flawed results. Likewise, creating a national average for a political poll based on the response from upper-middle-class individuals will also produce erroneous results.
All data sets will, by nature, contain a certain amount of bias. This bias must be taken into account within analytics and corresponding AI.
Bias In Evaluating Or Creating the Data

Conway’s Law
One of the most dangerous aspects of data analytics that can lead to catastrophic results in AI concerns the biases inherent within the controlling group.
In 1968, Melvin Conway, a computer programmer, postulated in a paper that ‘organizations which design systems (in the broad sense used here) are constrained to produce designs which are copies of the communication structures of these organizations.1
This brief statement became known as Conway’s law2 and elucidates how bias will always appear in systems. It is still relevant today, as it defines human behavior. The systems inherit the bias of the creators. If one wishes to use the term, they imitate those that created them — ‘clones.’
Among other aspects, Amy Webb’s research in AI concentrates on this bias, as it is fundamental to correct AI implementation. As she wisely states:
‘in the absence of meaningful explanations, what proof do we have that bias hasn’t crept in? Without knowing the answer to that question, how would anyone possibly feel comfortable trusting AI?’.3
As Webb points out in her evaluation of a Harvard Business School analysis of codebases:
‘One of their key findings: design choices stem from how their teams are organized, and within those teams, bias and influence tend to go overlooked. As a result, a small super network of individuals on a team wield tremendous power once their work — whether that’s a comb, a sink, or an algorithm — is used by or on the public…
Therefore, Conway’s law prevails, because the tribe’s values — their beliefs, attitudes, and behaviors as well as their hidden cognitive biases — are so strongly entrenched.’4
The Control Group's Bias
However, the issue of bias does not end there. Bias can appear in the actual data sets used because of how data was initially defined.
‘Since researchers can’t just scrape and load “ocean data” into a machine-learning system for training, they will buy a synthetic data set from a third party or build one themselves. This is often problematic because composing that data set — what goes into it and how it’s labelled — is rife with decisions made by a small number of people who often aren’t aware of their professional, political, gender, and many other cognitive biases.’5
In 1956, Dartmouth College hosted the first conference dedicated to AI.6 The term ‘artificial intelligence’ is credited to John McCarthy,7 conference leader and one of the proposal’s original authors. Unfortunately, the initial group was fundamentally flawed, being riddled with bias. It had no people of color and only one woman among 47 eminent participants — even though many experts of color and women were available. The answer to team creation without bias is pretty obvious.
‘A truly diverse team would have only one primary characteristic in common: talent. There would not be a concentration of any single gender, race, or ethnicity. Different political and religious views would be represented.’8
However, to achieve non-biased data, the law of ‘talent’ must be universally applied, and this is not a realistic goal.
Human nature will always produce some type of bias, no matter how much one prides oneself on being non-biased and politically correct. Bias is inherent in everything people do; it expresses one’s individualism.
To complicate matters, what is a bias for one culture and society? What is considered logical, objective, and fair for another? For instance, even in our modern, supposedly enlightened world, a ‘gay’ individual may not be allowed to participate in any representative group. Or gender bias may be part of the society, culture, and religion predominant in a specific country.
To give two simple examples:
The age at which one is legally allowed to consume alcohol varies wildly from area to area. Any data set inclusive of these different ages and regions measuring the effects of alcohol consumption that do not consider this factor of legal age will be fundamentally flawed if applied on a general level.
The age at which one is legally allowed to drive varies wildly from area to area. The same problems that exist in our first example here. Any data set on accidents involving new, young, teenage, or post-teenage drivers must consider this factor.
In both straightforward cases, it would be easy to fall into preconceived notions and produce faulty analytics.
It is critical for us to remember that ‘Bias’ will never contain a one-meaning-solves-all definition.
Detecting if bias is apparent in any construct depends on how that specific subculture defines bias and how that definition is implemented within the system. Bias will never be eradicated, although it is, by any definition, always a negative factor.
Data analytics must, therefore, consider the bias and build a myriad of defenses to counter it. Failure to do so will lead to erroneous results and a catastrophically flawed AI.
GroupThink
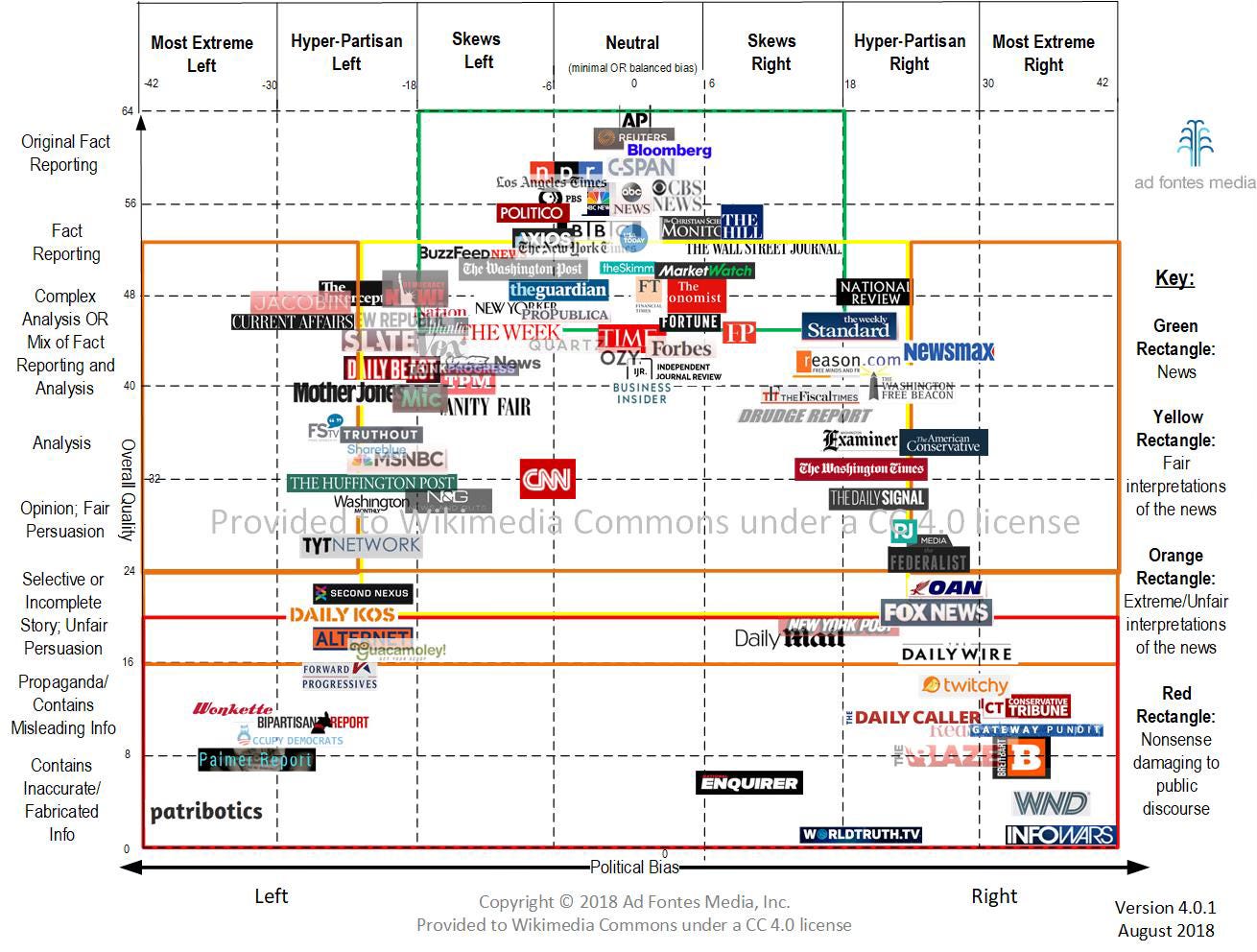
As discussed above, an outgrowth of Conway’s Law is a psychological phenomenon known as “Groupthink.”
“Groupthink is a psychological phenomenon that occurs within a group of people in which the desire for harmony or conformity in the group results in an irrational or dysfunctional decision-making outcome. Cohesiveness, or the desire for cohesiveness, in a group may produce a tendency among its members to agree at all costs. This causes the group to minimize conflict and reach a consensus decision without critical evaluation.”9
Groupthink reared its head during the Clinton-Trump United States Presidential Election of 2016. Before the results became clear, very few could even imagine a Trump victory. Even Donald Trump himself ‘expected, based on polling, to lose the election, and rented a small hotel ballroom to make a brief concession speech, later remarking: “I said if we’re going to lose, I don’t want a big ballroom.”’10
Nevertheless, despite being fully aware of this psychological phenomenon, it was dominant throughout the United States and the world. Donald Trump would never and could not win the election.
In the weeks and months preceding the 2016 United States presidential election, there was near-unanimity among news media outlets and polling organizations that Hillary Clinton’s election was extremely likely. For example, on November 7, the day before the election, The New York Times opined that Clinton then had “a consistent and clear advantage in states worth at least 270 electoral votes.” The Times estimated the probability of a Clinton win at 84%. Also on November 7, Reuters estimated the probability of Clinton defeating Donald Trump in the election at 90%, and The Huffington Post put Clinton’s odds of winning at 98.2% based on “9.8 million simulations”.
The contradiction between the election results and the pre-election estimates, both from news media outlets and from pollsters, may have been due to two factors: news and polling professionals could not imagine a candidate as unconventional as Trump becoming president, and Trump supporters may have been undersampled by surveys, or may have lied to or misled pollsters out of fear of social ostracism.11
There are hundreds of reasons why the data was faulty. The pollsters were prejudiced. The newspapers fell for their rhetoric. The polled voters did not want to answer for fear of ridicule or purposely gave false answers out of disdain for the polls. Nevertheless, bias was apparent from the outset, and no one was willing to face it.
Groupthink has reared its head throughout history. Decisions are often made based on faulty data analysis or a refusal to face what the “real data” depicts. In the corporate world, this can often lead to catastrophic results, either in the loss of hundreds of millions of dollars or forcing the closure of a company.
Examples of Groupthink abound in the history of warfare. Erroneous assumptions are made based on inaccurate data, resulting in the loss of life. The invasion of Iraq after 9/11 is a perfect example of this. The failure of the United States to adequately protect and defend Pearl Harbor before the Japanese attacked on Dec. 7th, 1941 — despite the many warnings and signals of an imminent attack — was the result of Groupthink. The data was there. The military and political leaders analyzed it. The Bias crept in, as it was believed the Japanese would never have the courage to attack the United States and force its entry into a World War.
Many believe the NASA disaster of the explosion of Challenger on takeoff was an example of Groupthink. The data was available. NASA was aware of the detrimental effects of freezing temperatures on the shuttle. Warnings were voiced and given. Yet, when meeting together, the heads of NASA gave the green light for Challenger to take off.
We can give an example after example of Conway’s Law and Groupthink. However, one thing remains clear.
The human condition will always contain bias. Bias is part of being human. Data sets will reflect that bias. And if we do not create the correct algorithms and corrective analysis for bias, we will always end up with flawed analytics.
So there you have it. Bias, GroupThink, and how it affects your POV. Remember, nothing you write is “pure objective truth.” It is much worse when you knowingly or unknowingly quote sources that are just lies or present a POV and call that “objective truth.”
There is way too much on Substack being presented as objective truth about the war in Israel that is based on misinformation, lies, or fake news. Way too much, on both sides, that does not reflect reality.
So let us restate the above.
The human condition will always contain bias. Bias is part of being human.
Our writing will reflect that bias. GroupThink will further complicate that Bias and distort truth and opinions.
If we do not create the correct algorithms and corrective analysis for bias within our minds and develop the correct methods to understand and sift through this information, we will always end up with flawed and sometimes even dangerous opinions.
Enough said. I hope the message is clear.
Conway, M. E. (1968) ‘How do committees invent?’, Datamation, Vol. 14, №5, pp. 28–31.
Wikipedia (n.d.) ‘Conway’s law,’ available at: https://en.wikipedia.org/wiki/Conway’s_law (accessed 29th July 2021).
Webb, A. (2019) ‘The Big Nine: How the Tech Titans and Their Thinking Machines Could Warp Humanity’ PublicAffairs, New York, NY, Kindle Edition, Location 1763.
Ibid., Location 1666.
Ibid., Location 2763.
Wikipedia (n.d.) ‘Artificial intelligence,’ available at: https://en.wikipedia.org/w/index.php?title=Artificial_intelligence&oldid=997705860 (accessed 13th January 2021).
Wikipedia (n.d.) ‘John McCarthy (computer scientist),’ available at: https://en.wikipedia.org/wiki/John_McCarthy_(computer_scientist) (accessed 29th July 2021).
Webb, ref. 3 above, Location 893.
Wikipedia (n.d.) ‘Groupthink,’ available at: https://en.wikipedia.org/wiki/Groupthink (accessed 18th April 2022).
Wikipedia (n.d.) ‘2016 United States presidential election’, available at: https://en.wikipedia.org/wiki/2016_United_States_presidential_election (accessed 18th April 2022).
Wikipedia (n.d.) ‘Groupthink,’ available at: https://en.wikipedia.org/wiki/Groupthink#2016_United_States_presidential_election (accessed 18th April 2022).